在学习Go的过程中,最让人惊叹的莫过于goroutine了。但是goroutine是什么,我们用go关键字就可以创建一个goroutine,这么多的goroutine之间,是如何调度的呢?
结构概览
在看Go源码的过程中,遍地可见g、p、m,我们首先就看一下这些关键字的结构及相互之间的关系
数据结构
这里我们仅列出来了结构体里面比较关键的一些成员
G(gouroutine)
goroutine是运行时的最小执行单元
1 | type g struct { |
P(process)
P是M运行G所需的资源
1 | type p struct { |
M(machine)
1 | type m struct { |
sched
1 | type schedt struct { |
在这里插一下状态的解析
g.status
- _Gidle: goroutine刚刚创建还没有初始化
- _Grunnable: goroutine处于运行队列中,但是还没有运行,没有自己的栈
- _Grunning: 这个状态的g可能处于运行用户代码的过程中,拥有自己的m和p
- _Gsyscall: 运行systemcall中
- _Gwaiting: 这个状态的goroutine正在阻塞中,类似于等待channel
- _Gdead: 这个状态的g没有被使用,有可能是刚刚退出,也有可能是正在初始化中
- _Gcopystack: 表示g当前的栈正在被移除,新栈分配中
p.status
- _Pidle: 空闲状态,此时p不绑定m
- _Prunning: m获取到p的时候,p的状态就是这个状态了,然后m可以使用这个p的资源运行g
- _Psyscall: 当go调用原生代码,原生代码又反过来调用go的时候,使用的p就会变成此态
- _Pdead: 当运行中,需要减少p的数量时,被减掉的p的状态就是这个了
m.status
m的status没有p、g的那么明确,但是在运行流程的分析中,主要有以下几个状态
- 运行中: 拿到p,执行g的过程中
- 运行原生代码: 正在执行原声代码或者阻塞的syscall
- 休眠中: m发现无待运行的g时,进入休眠,并加入到空闲列表中
- 自旋中(spining): 当前工作结束,正在寻找下一个待运行的g
在上面的结构中,存在很多的链表,g m p结构中还有指向对方地址的成员,那么他们的关系到底是什么样的
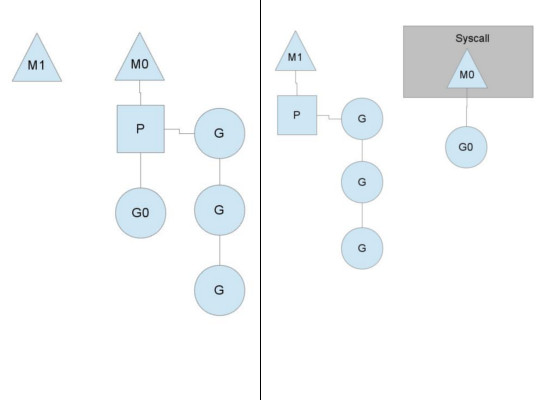
我们可以从上图,简单的表述一下 m p g的关系
流程概览
从下图,可以简单的一窥go的整个调度流程的大概
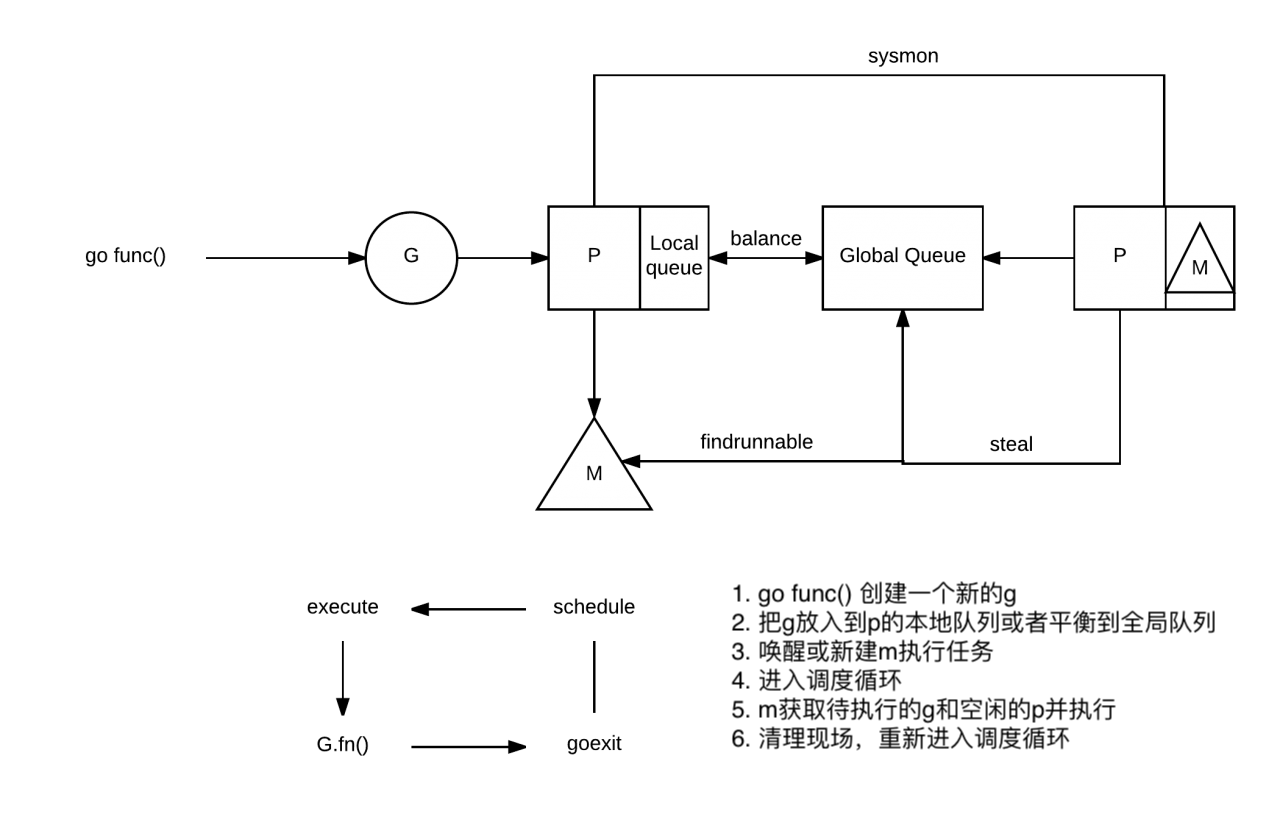
接下来我们就从源码的角度来具体的分析整个调度流程(本人汇编不照,汇编方面的就不分析了🤪)
源码分析
初始化
go的启动流程分为4步
- call osinit, 这里就是设置了全局变量ncpu = cpu核心数量
- call schedinit
- make & queue new G (runtime.newproc, go func()也是调用这个函数来创建goroutine)
- call runtime·mstart
其中,schedinit 就是调度器的初始化,出去schedinit 中对内存分配,垃圾回收等操作,针对调度器的初始化大致就是初始化自身,设置最大的maxmcount, 确定p的数量并初始化这些操作
schedinit
schedinit这里对当前m进行了初始化,并根据osinit获取到的cpu核数和设置的GOMAXPROCS 确定p的数量,并进行初始化
1 | func schedinit() { |
mcommoninit
1 | func mcommoninit(mp *m) { |
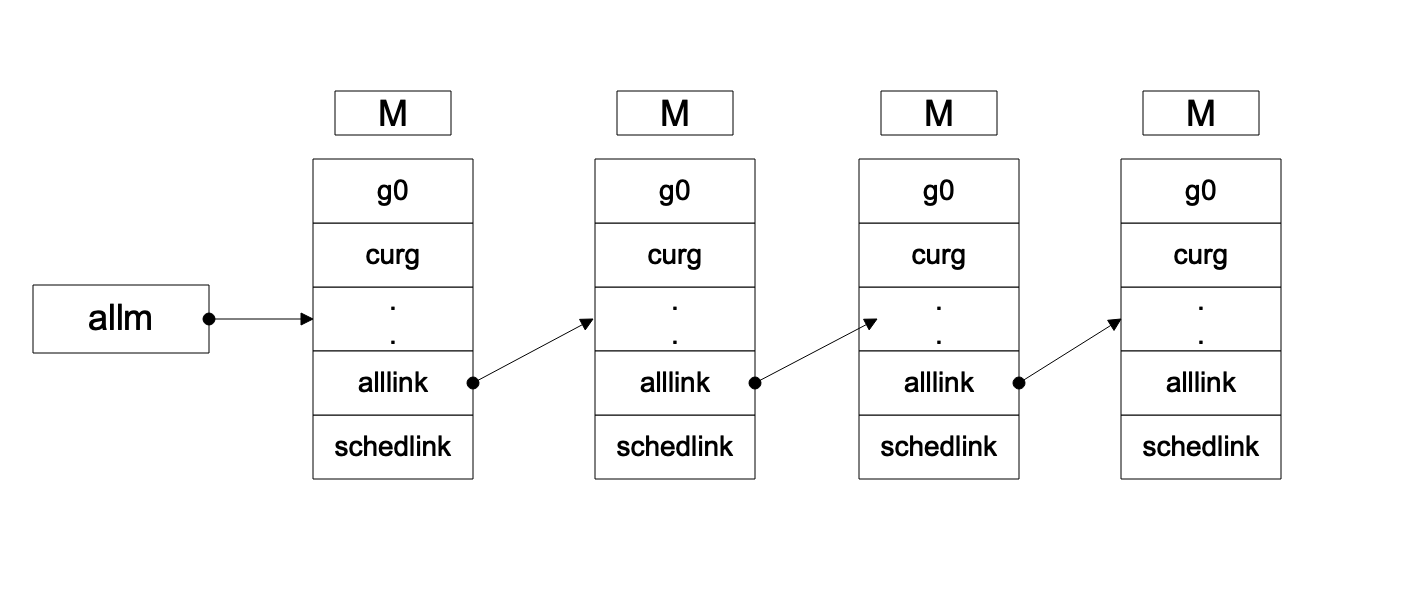
在这里就开始涉及到了m链表了,这个链表可以如下图表示,其他的p g链表可以参考,只是使用的结构体的字段不一样
3.1.1.2. allm链表示意图
3.1.1.3. procresize
更改p的数量,多退少补的原则,在初始化过程中,由于最开始是没有p的,所以这里的作用就是初始化设定数量的p了
procesize 不仅在初始化的时候会调用,当用户手动调用 runtime.GOMAXPROCS 的时候,会重新设定 nprocs,然后执行 startTheWorld(), startTheWorld()会是使用新的 nprocs 再次调用procresize 这个方法
1 | func procresize(nprocs int32) *p { |
- runqempty: 这个函数比较简单,就不深究了,就是根据 p.runqtail == p.runqhead 和 p.runnext 来判断有没有待运行的g
- pidleput: 将当前的p设置为 sched.pidle,然后根据p.link将空闲p串联起来,可参考上图allm的链表示意图
任务
创建一个goroutine,只需要使用 go func 就可以了,编译器会将go func 翻译成 newproc 进行调用,那么新建的任务是如何调用的呢,我们从创建开始进行跟踪
newproc
newproc 函数获取了参数和当前g的pc信息,并通过g0调用newproc1去真正的执行创建或获取可用的g
1 | func newproc(siz int32, fn *funcval) { |
newproc1
newporc1 的作用就是创建或者获取一个空间的g,初始化这个g,并尝试寻找一个p和m去执行g
1 | func newproc1(fn *funcval, argp *uint8, narg int32, callergp *g, callerpc uintptr) { |
gfget
这个函数的逻辑比较简单,就是看一下p有没有空闲的g,没有则去全局的freeg队列查找,这里就涉及了p本地和全局平衡的一个交互了
1 | func gfget(_p_ *p) *g { |
runqput
runqput会把g放到p的本地队列或者p.runnext,如果p的本地队列过长,则把g到全局队列,同时平衡p本地队列的一半到全局
1 | func runqput(_p_ *p, gp *g, next bool) { |
runqputslow
1 | func runqputslow(_p_ *p, gp *g, h, t uint32) bool { |
新建任务至此基本结束,创建完成任务后,等待调度执行就好了,从上面可以看出,任务的优先级是 p.runnext > p.runq > sched.runq
g从创建到执行结束并放入free队列中的状态转换大致如下图所示
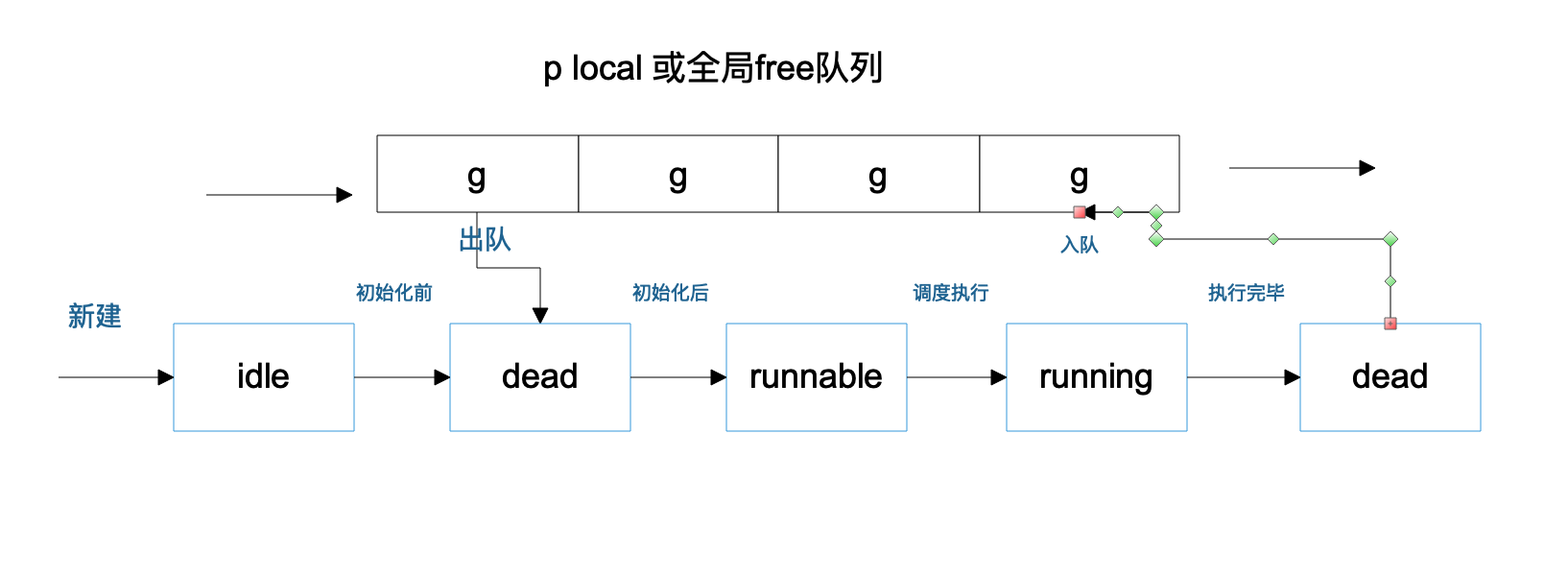
wakep
当 newproc1创建完任务后,会尝试唤醒m来执行任务
1 | func wakep() { |
startm
调度m或者创建m来运行p,如果p==nil,就会尝试获取一个空闲p,p的队列中有g,拿到p后才能拿到g
1 | func startm(_p_ *p, spinning bool) { |
newm
newm 通过allocm函数来创建新m
1 | func newm(fn func(), _p_ *p) { |
new1m
1 | func newm1(mp *m) { |
newosproc
newosproc 创建一个新的系统线程,并执行mstart_stub函数,之后调用mstart函数进入调度,后面在执行流程会分析
1 | func newosproc(mp *m) { |
allocm
allocm这里首先会释放 sched的freem,然后再去创建m,并初始化m
1 | func allocm(_p_ *p, fn func()) *m { |
notewakeup
1 | func notewakeup(n *note) { |
至此的话,创建完任务g后,将g放入了p的local队列或者是全局队列,然后开始获取了一个空闲的m或者新建一个m来执行g,m, p, g 都已经准备完成了,下面就是开始调度,来运行任务g了
执行
在startm函数分析的过程中会,可以看到,有两种获取m的方式
- 新建: 这时候执行newm1下的newosproc,同时最终调用mstart来执行调度
- 唤醒空闲m:从休眠的地方继续执行
m执行g有两个起点,一个是线程启动函数 mstart, 另一个则是休眠被唤醒后的调度schedule了,我们从头开始,也就是mstart, mstart 走到最后也是 schedule 调度
mstart
1 | func mstart() { |
mstart1
1 | func mstart1() { |
acquirep
acquirep 函数主要是改变p的状态,绑定 m p,通过吧p的mcache与m共享
1 | func acquirep(_p_ *p) { |
acquirep1
1 | func acquirep1(_p_ *p) { |
schedule
开始进入到调度函数了,这是一个由schedule、execute、goroutine fn、goexit构成的逻辑循环,就算m是唤醒后,也是从设置的断点开始执行
1 | func schedule() { |
stoplockedm
因为当前的m绑定了lockedg,而当前g不是指定的lockedg,所以这个m不能执行,上交当前m绑定的p,并且休眠m直到调度lockedg
1 | func stoplockedm() { |
startlockedm
调度 lockedm去运行lockedg
1 | func startlockedm(gp *g) { |
handoffp
1 | func handoffp(_p_ *p) { |
execute
开始执行g的代码了
1 | func execute(gp *g, inheritTime bool) { |
gogo
gogo函数承载的作用就是切换到g的栈,开始执行g的代码,汇编内容就不分析了,但是有一个疑问就是,gogo执行完函数后,怎么再次进入调度呢?
我们回到newproc1函数的L63 newg.sched.pc = funcPC(goexit) + sys.PCQuantum ,这里保存了pc的质地为goexit的地址,所以当执行完用户代码后,就会进入 goexit 函数
goexit0
goexit 在汇编层面就是调用 runtime.goexit1,而goexit1通过 mcall 调用了goexit0 所以这里直接分析了goexit0
goexit0 重置g的状态,并重新进行调度,这样就调度就又回到了schedule() 了,开始循环往复的调度
1 | func goexit0(gp *g) { |
至此,单次调度结束,再次进入调度,循环往复
findrunnable
1 | func findrunnable() (gp *g, inheritTime bool) { |
这里真的是无奈啊,为了寻找一个可运行的g,也是煞费苦心,及时进入了stop 的label,还是不死心,又来了一边寻找。大致寻找过程可以总结为一下几个:
- 从p自己的local队列中获取可运行的g
- 从全局队列中获取可运行的g
- 从netpoll中获取一个已经准备好的g
- 从其他p的local队列中获取可运行的g,随机偷取p的runnext,有点任性
- 无论如何都获取不到的话,就stopm了
stopm
stop会把当前m放到空闲列表里面,同时绑定m.nextp 与 m
1 | func stopm() { |
监控
sysmon
go的监控是依靠函数 sysmon 来完成的,监控主要做一下几件事
- 释放闲置超过5分钟的span物理内存
- 如果超过两分钟没有执行垃圾回收,则强制执行
- 将长时间未处理的netpoll结果添加到任务队列
- 向长时间运行的g进行抢占
- 收回因为syscall而长时间阻塞的p
监控线程并不是时刻在运行的,监控线程首次休眠20us,每次执行完后,增加一倍的休眠时间,但是最多休眠10ms
1 | func sysmon() { |
扫描netpoll,并把g存放到去全局队列比较好理解,跟前面添加p和m的逻辑差不多,但是抢占这里就不是很理解了,你说抢占就抢占,被抢占的g岂不是很没面子,而且怎么抢占呢?
retake
1 | const forcePreemptNS = 10 * 1000 * 1000 // 10ms |
preemptone
这个函数的注释,作者就表明这种抢占并不是很靠谱😂,我们先看一下实现吧
1 | func preemptone(_p_ *p) bool { |
在这里,作者会更新 gp.stackguard0 = stackPreempt,然后让g误以为栈不够用了,那就只有乖乖的去进行栈扩张,站扩张的话就用调用newstack 分配一个新栈,然后把原先的栈的内容拷贝过去,而在 newstack 里面有一段如下
1 | if preempt { |
然后这里就发现g被抢占了,那你栈不够用就有可能是假的,但是管你呢,你再去调度去吧,也不给你扩栈了,虽然作者和雨痕大神都吐槽了一下这个,但是这种抢占方式自动1.5(也可能更早)就一直存在,且稳定运行,就说明还是很牛逼的了
总结
在调度器的设置上,最明显的就是复用:g 的free链表, m的free列表, p的free列表,这样就避免了重复创建销毁锁浪费的资源
其次就是多级缓存: 这一块跟内存上的设计思想也是一直的,p一直有一个 g 的待运行队列,自己没有货过多的时候,才会平衡到全局队列,全局队列操作需要锁,则本地操作则不需要,大大减少了锁的创建销毁所消耗的资源
至此,g m p的关系及状态转换大致都讲解完成了,由于对汇编这块比较薄弱,所以基本略过了,右面有机会还是需要多了解一点
参考文档
《go语言学习笔记》