在使用map的过程中,有两个问题是经常会遇到的:读写冲突和遍历无序性。为什么会这样呢,底层是怎么实现的呢?带着这两个问题,我简单的了解了一下map的增删改查及遍历的实现。
结构
hmap
1 | type hmap struct { |
mapextra
1 | type mapextra struct { |
bmap
1 | type bmap struct { |
stringStruct
1 | type stringStruct struct { |
hiter
map遍历时用到的结构,startBucket+offset设定了开始遍历的地址,保证map遍历的无序性
1 | type hiter struct { |
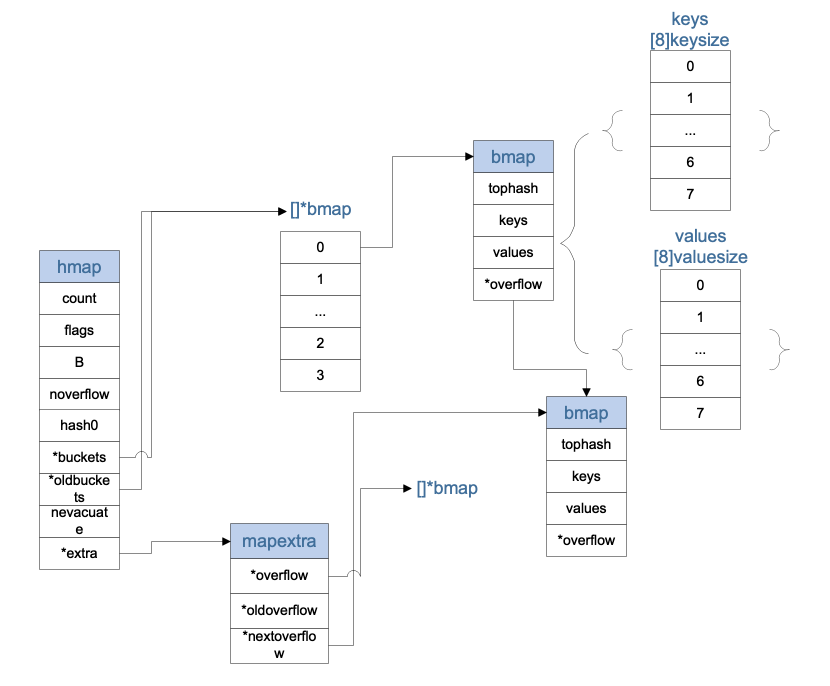
这里的keys和values、*overflow三个变量在结构体中并没有体现,但是在源码过程中,一直有为他们预留位置,所以这里的示意图中就展示出来了,keys和values其实8个长度的数组
demo
我们简单写个demo,通过go tool 来分析一下底层所对应的函数
1 | func main() { |
1 | ▶ go tool objdump -s "main.main" main | grep CALL |
初始化
makemap
makemap创建一个hmap结构体,并赋予这个变量一些初始的属性
1 | func makemap(t *maptype, hint int, h *hmap) *hmap { |
##makeBucketArray
makeBucketArray初始化了map所需的buckets,最少分配2^b个buckets
1 | func makeBucketArray(t *maptype, b uint8, dirtyalloc unsafe.Pointer) (buckets unsafe.Pointer, nextOverflow *bmap) { |
初始化的过程到此就结束了,比较简单,就是根据初始化的大小,确定buckets的数量,并分配内存等
查找(mapaccess)
在上面的go tool 分析过程中可以发现
- _ = m[“444”] 对应
mapaccess1 - _, _ = m[“444”] 对应
mapaccess2
两个函数的逻辑大致相同,我们以mapaccess1为例来分析
mapaccess
1 | func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer { |
overflow
这个函数就是找bmap的overflow的地址,通过结构图中可以看出,找到bmap结构体的最后一个指针占用的内存单元就是overflow指向的下一个bmap的地址了
1 | func (b *bmap) overflow(t *maptype) *bmap { |
上面的逻辑比较简单,但是在这里有几个问题需要解决
- bucket(bmap结构体)是怎么确定的
- tophash是怎么确定的
- key和value的地址为什么是通过偏移来计算的
先放一下buckets和bmap的放大图
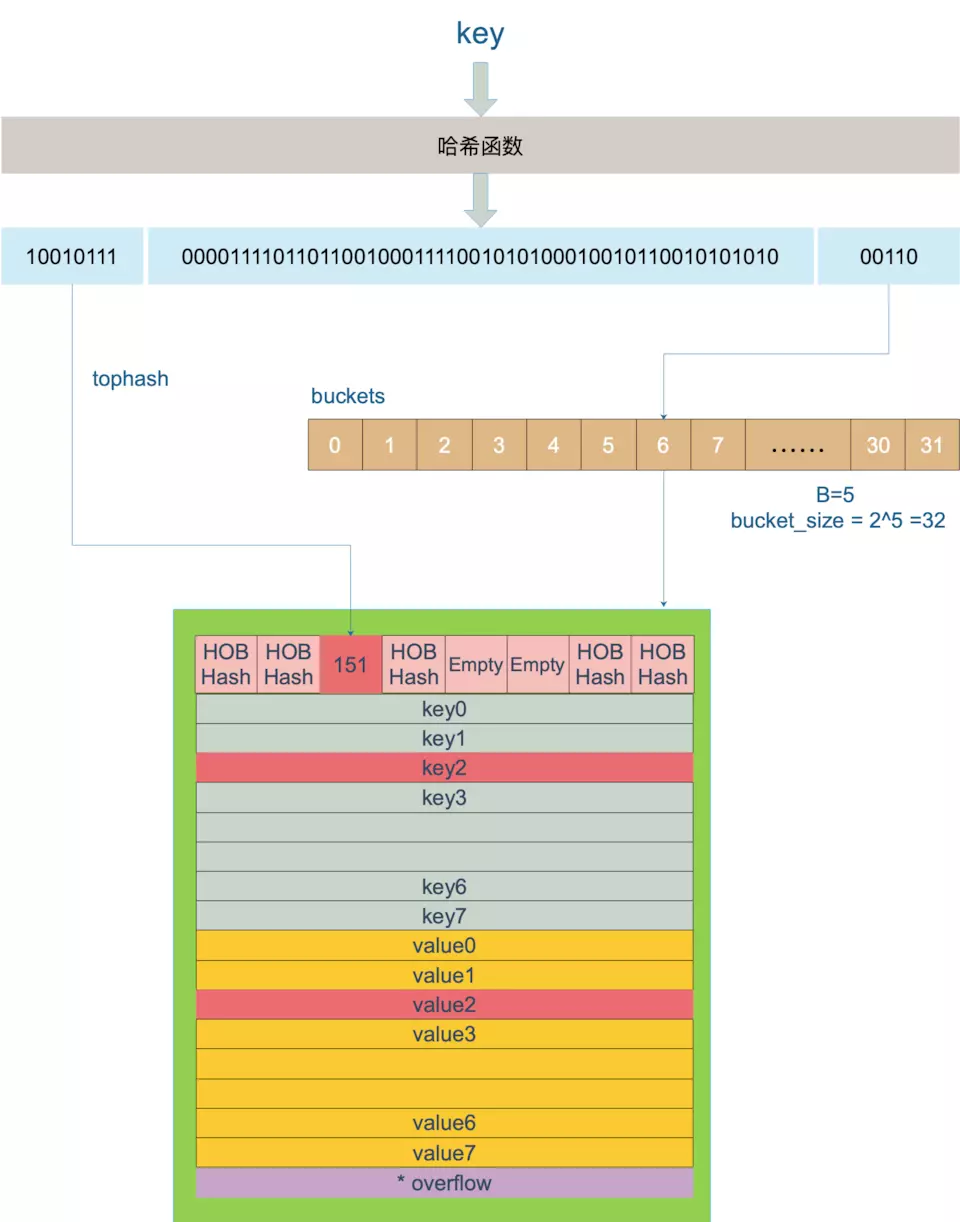
bucket(bmap结构体)是怎么确定的
1
2bucket := hash & bucketMask(h.B)
b := (*bmap)(unsafe.Pointer(uintptr(h.buckets) + bucket*uintptr(t.bucketsize)))加入B=5,则说明buckets的数量为2^5 = 32,则取hash的末5位,来计算出目标bucket的索引,图中计算出索引为6,所以,在buckets上偏移6个bucket大小的地址,即可找到对应的bucket
tophash是怎么确定的
1
2
3
4
5
6
7func tophash(hash uintptr) uint8 {
top := uint8(hash >> (sys.PtrSize*8 - 8))
if top < minTopHash {
top += minTopHash
}
return top
}每个bucket的tophash数组的长度为8,所以,这里直接去hash值的前8位计算出来数值,既是tophash了
key和value的地址为什么是通过偏移来计算的
1
2k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
val = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))根据最开始的数据结构分析和上面的bmap图示,可以看出bmap中所有的key是放在一起的,所有的value是放在一起的,dataoffset是tophash[8]所占用的大小,所以,key所在的地址也就是 b的地址+dataOffset的偏移+对应的索引i*key的大小,同理value是排列在key的后面的
插入
mapassign
1 | func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer { |
setoverflow
1 | func (h *hmap) newoverflow(t *maptype, b *bmap) *bmap { |
overflow指向的就是一个bmap结构,而bmap结构的最后一个地址,存储的是overflow的地址,通过bmap.overflow可以将bmap的所有overflow串联起来,hmap.extra.nextOverflow也是一样的逻辑
扩容
在mapassign函数中可以看到,扩容发生的情况有两种
1 | overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B) |
- 超过设定的负载值
- 有太多的overflow
先来看一下这两个函数
overLoadFactor
1 | func overLoadFactor(count int, B uint8) bool { |
uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen) 可以简化为 count / (2^B) > 6.5, 这个6.5便是代表loadFactor的负载系数
##tooManyOverflowBuckets
1 | func tooManyOverflowBuckets(noverflow uint16, B uint8) bool { |
通过判断noverflow的数量来判断overflow是否太多
我们理解一下这两种情况扩容的原因
超过设定的负载值
根据key查找的过程中,根据末B位确定bucket,高8位确定tophash,但是查找tophash的过程中,是需要遍历整个bucket的,所以,最优的情况是每个bucket只存储一个key,这样就达到了hash的O(1)的查找效率,但是空间却大大的浪费了;如果所有的key都存储到了一个bucket里面面,就退变成了链表,查找效率就变成了O(n),所以装载系数就是为了平衡查找效率和存储空间的,当装载系数过大,就需要增加bucket了,来提高查找效率,即增量扩容
有太多的overflow
当bucket的空位全部填满的时候,装载系数就达到了8,为什么还会有tooManyOverflowBuckets的判断呢,map不仅有增加还有删除的操作,当某一个bucket的空位填满后,开始填充到overflow里面,这时候再删除bucket里面的数据,其实整个过程很有可能并没有触发 超过负载扩容机制的,(因为有较多的buckets),但是查找overflow的数据,就首先要遍历bucket的数据,这个就是无用功了,查找效率就低了,这时候需要不增加bucket数量的扩容,也就是等量扩容
扩容的工作是由hashGrow开始的,但是真正进行迁移工作的是evacuate, 由growWork进行d调用;在每一次的maassign和mapdelete的时候,会判断这个map是否正在进行扩容操作,如果是的,就迁移当前的bucket;所以,map的扩容并不是一蹴而就的,而是一个循序渐进的过程
hashGrow
1 | func hashGrow(t *maptype, h *hmap) { |
hashGrow 这个前菜已经准备完成了,接下来就交给growWork和 evacuate两个函数来完成的
growWork
1 | func growWork(t *maptype, h *hmap, bucket uintptr) { |
###evacuate
讲hmap中的一个bucket搬移到新的buckets中,老的bucket里key与新的buckets中位置的对应,同样参考map的查找过程
这里如何判断这个bucket是否已经搬移过了呢,主要就是依据evacuated函数来判断
1 | func evacuated(b *bmap) bool { |
看了源码就发现原理很简单,就是对tophash[0]值的判断,那么肯定是在搬移之后设置的这个值,我们通过evacuate函数l哎一探究竟吧
1 | func evacuate(t *maptype, h *hmap, oldbucket uintptr) { |
扩容是逐步进行的,一次搬运一个bucket
我们以原先的B=5为例,现在增量扩容后B=6,但是hash的倒数第6位只能是0或1,也就是说,如果原先计算出来的bucket索引为6的话,即 00110,那么新的bucket对应的索引只能是 100110(6+2^5)或 000110(6),x对应的就是6,y对应的就是(6+2^5);如果是等量扩容,那么索引肯定就是不变的,这时候就不需要y了
找到对应的新的bucket之后,按顺序依次存放就ok了
删除
mapdelete
删除的逻辑比较简单,根据key查找,找到就清空key和value及tophash
1 | func mapdelete(t *maptype, h *hmap, key unsafe.Pointer) { |
遍历
按一般的思维来考虑,遍历值需要遍历buckets数组里面的每个bucket以及bucket下挂的overflow链表即可,但是map存在扩容的情况,这样就会导致遍历的难度增大了,我们看一下go是怎么实现的
根据go tool 的分析,我们可以简单看一下遍历时的流程信息
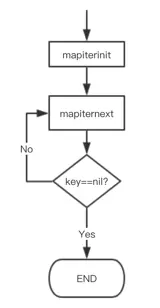
mapiterinit
1 | func mapiterinit(t *maptype, h *hmap, it *hiter) { |
mapiternext
1 | func mapiternext(it *hiter) { |
整体思路如下:
- 首先从buckets数组中,随机确定一个索引,作为startBucket,然后确定offset偏移量,作为起始key的地址
- 遍历当前bucket及bucket.overflow,判断当前bucket是否正在扩容中,如果是则跳转到3,否则跳转到4
- 加入原先的buckets为0,1,那么扩容后的新的buckets为0,1,2,3,此时我们遍历到了buckets[0], 发现这个bucket正在扩容,那么找到bucket[0]所对应的oldbuckets[0],遍历里面的key,这时候是遍历所有的吗?当然不是,而是仅仅遍历那些key经过hash,可以散列到bucket[0]里面的部分key;同理,当遍历到bucket[2]的时候,发现bucket正在扩容,找到oldbuckets[0],然后遍历里面可以散列到bucket[2]的那些key
- 遍历当前这个bucket即可
- 继续遍历bucket下面的overflow链表
- 如果遍历到了startBucket,说明遍历完了,结束遍历