Sentinel(哨兵)是Redis 的高可用性解决方案:由一个或多个Sentinel 实例 组成的Sentinel 系统可以监视任意多个主服务器,以及这些主服务器属下的所有从服务器,并在被监视的主服务器进入下线状态时,自动将下线主服务器属下的某个从服务器升级为新的主服务器。
在介绍哨兵之前,我们先看一下一些中小型的Redis的一个简单的主从架构
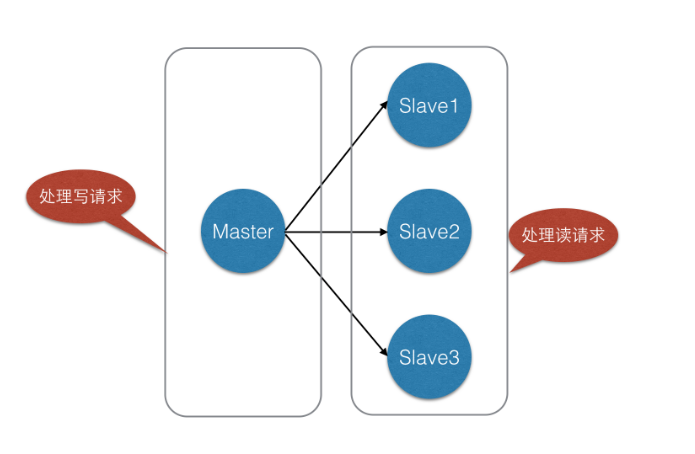
我们的程序,在进程写入操作的时候,可能会直连Master,但是,如果这时候Master宕了,就会导致数据写入不进去,而等我们反应过来并处理好,说不定十几分钟甚至更长时间就过去了。但是,如果我们引入哨兵,采用下面的架构
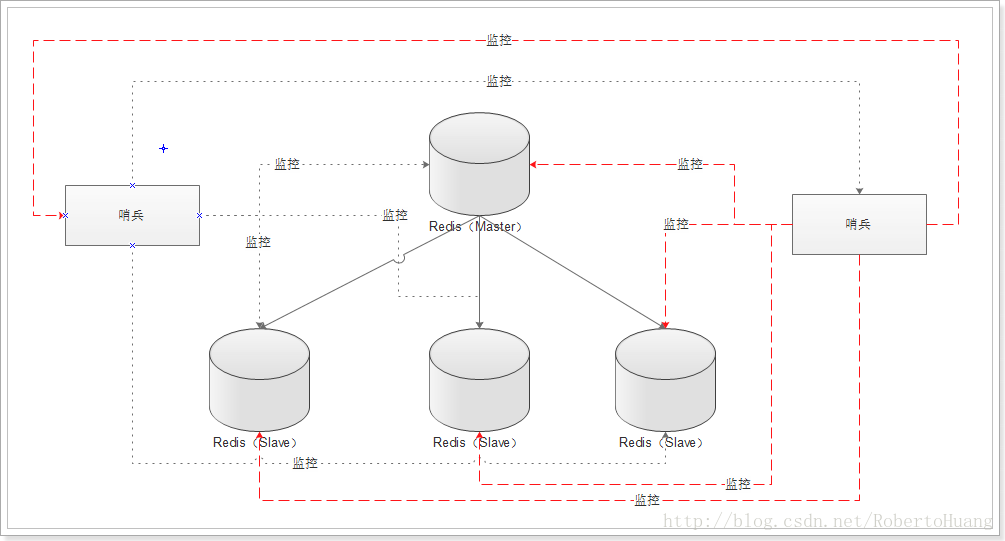
我们设置多台哨兵,我们的程序去连接哨兵,加入Master宕掉了,哨兵们去帮我们选一台Slave当新的Master,这样也就能实现快速的故障转移及处理了,毕竟线上是耽误不起每分每秒的。
简介
Redis-Sentinel是用于管理Redis集群,该系统执行以下三个任务:
- 监控(Monitoring):Sentinel会不断地检查你的主服务器和从服务器是否运作正常
- 提醒(Notification):当被监控的某个Redis服务器出现问题时,Sentinel可以通过API向管理员或者其他应用程序发送通知
- 自动故障迁移(Automatic failover):当一个主服务器不能正常工作时,Sentinel 会开始一次自动故障迁移操作,它会将失效主
服务器的其中一个从服务器升级为新的主服务器,并让失效主服务器的其他从服务器改为复制新的主服务器;当客户端试图连接失效的主服务器时,集群也会向客户端返回新主服务器的地址,使得集群可以使用新主服务器代替失效服务器
搭建
Redis2.8和3.0已经附带了稳定版本的哨兵,通过yum安装后,在redis-server的同一目录下会有一个redis-sentinel的可执行脚本,这个就是Redis的哨兵了,后面用sentinel来代替哨兵这个名词,因为这是人家的正式的名字。
配置
在/etc/目录下,也就是redis.conf的同级目录下,会有一个redis-sentinel.conf , 这个就是 sentinel 的配置文件
我们通过下面的命令查看一下他的主要内容
1 | cat sentinel-26379.conf | grep -v "#" | grep -v "^$" |
输出如下(# 为我的注释):
1 | # 哨兵监听的端口 |
注:
我们一般以守护进程的方式开启哨兵,但是配置文件里面没有写,我们可以在配置文件的开始加上
1 | daemonize yes |
实战
主从配置
了解了上面的配置后,我们可以先撘一个主从服务器
思路如下:
- 开启三台服务器,分别监听 6379 6380 6381 端口
- 将6379 设置为master, 6380和6381 分别slaveof 6379
6379.conf
1 | bind 127.0.0.1 |
6380的配置
1 | bind 127.0.0.1 |
6381的配置与6380基本相同,只是修改一下端口和log,rdb,aof的名字而已
然后我们开启了三台redis,并且设置好了主从关系
redis-server /path/to/6379.conf
redis-server /path/to/6380.conf
redis-server /path/to/6381.conf
哨兵配置
思路如下:
- 我们一样开启三台 sentinel 分别监听 26379 26380 26381
- 将这三台 sentinel 全部监控我们的master 6379端口的Redis
26379.conf
1 | port 26379 |
其余两个配置,除端口和logfile外,均一样,可参考着写
然后我们开启这三台哨兵
redis-sentinel /path/to/26379.conf
redis-sentinel /path/to/26380.conf
redis-sentinel /path/to/26381.conf
分析日志
我们查看任一个哨兵的日志,启动后可以发现,日志里面输入了一下内容
1 | 2739:X 23 May 09:00:15.188 # Sentinel ID is 41b05827fdb8f7f8e88e74aa7070190c3c8f84f6 |
也就是说sentinel 跟我我们配置的 找到了master ,并且找到了另外的两台 Sentinel ,这时候,我们去看 我们原先配置的 sentinel 的配置文件,应该也发生了变化
1 | # Generated by CONFIG REWRITE |
这时候,Sentinel 集群监控已经开启并且开始监控了。
那么,Sentinel 是如何工作的呢,又是怎么投票选举新的master的呢,其实还是要继续依赖他锁打印的日志
我们这时候,主动下线一台,然后继续分析一下 Sentinel 的日志
redis-cli -p 6379 shutdown
这时候,日志又会继续打印内容
1 | 2739:X 23 May 09:05:02.978 # +sdown master mymaster 127.0.0.1 6379 |
流程可参考:
- Sentinel 发现了master宕掉了
- 然后给另一台 slave 投票了
- 另外一个又发现 master 宕了,超过我们的设定了
- 开始协商:某个时间点之后 master还没有起,我们就另立新主吧
- 哎哟歪,时间到了,我们把其他的配置文件都更新一下吧,不然重启了我们的决议又失效了咋办
- 最后,我们欢迎新主降临
我们这时候把6379再开启,又会发生什么情况了
1 | 2739:X 23 May 09:05:04.209 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6381 |
其实,在上面的宕机并另立master的时候 6379 的配置已经被 Sentinel 修改了,这时候,就只有乖乖的当 slave了