数组是PHP中非常强大、灵活的一种数据类型,它的底层实现为散列表(HashTable,也称作:哈希表),除了我们熟悉的PHP用户空间的Array类型之外,内核中也随处用到散列表,比如函数、类、常量、已include文件的索引表、全局符号表等都用的HashTable存储。
散列表是根据关键码值(Key value)而直接进行访问的数据结构,它的key - value之间存在一个映射函数,可以根据key通过映射函数直接索引到对应的value值,它不以关键字的比较为基本操作,采用直接寻址技术(就是说,它是直接通过key映射到内存地址上去的),从而加快查找速度,在理想情况下,无须任何比较就可以找到待查关键字,查找的期望时间为O(1)。
数组结构
Array 结构体(zend_type.h)
1 | struct _zend_array { |
这个了结构体里面 在第2行 引入了 zend_refcounted_h 结构体,这个是垃圾回收时用到的
在第14行的时候 引入了 Bucket 结构体,我们继续看一下 Bucket 结构体
Bucket结构体 (zend_type.h)
1 | typedef struct _Bucket { |
在第2行的时候,引入了 zval 结构体,
zval结构体(zend_type.h)
1 | struct _zval_struct { |
字段解释
首先从 array结构体开始说起
- nTableMask : 哈希值计算掩码, 数组的索引计算出来的long 与这个值进行位运算,从而计算出这个数据应该存放在索引表的位置
- arData: 数组中的值都存放在这里,这个也是数组hash表的实现的地方
- nNumUsed: 使用的bucket的总数
- nNumOfElements: hash表中的有效数据,在PHP中,删除数组中的一个元素,并不会直接将这个元素从hash表里面删除,而是在bucket里面的zval结构体里面修改为
IS_UNDEF, 在ht->nNumUsed > ht->nNumOfElements + (ht->nNumOfElements >> 5)的时候进行整理 - nTableSize: 分配的hash表的大小
- nNextFreeElement: 下一个可用的hash数值索引
- pDestructor: 一个回调函数,当覆盖/删除一个key或者释放zend_array时,用于释放Bucket中的val。
Bucket
- val:存储的zval数据。
- h:当元素保存在整形下标时,下标保存在该字段,并且本身充当hash值,对其取模得到哈希表的槽位。
- key:当保存的key是字符串时,保存在该字段,通过某个哈希算法生成hash值保存到h字段,对h取模得到哈希表的槽位。
hash表
hash表图示
首先在这里展示一下,数组的hash表大致的实现图示,然后结合插入操作来具体分析
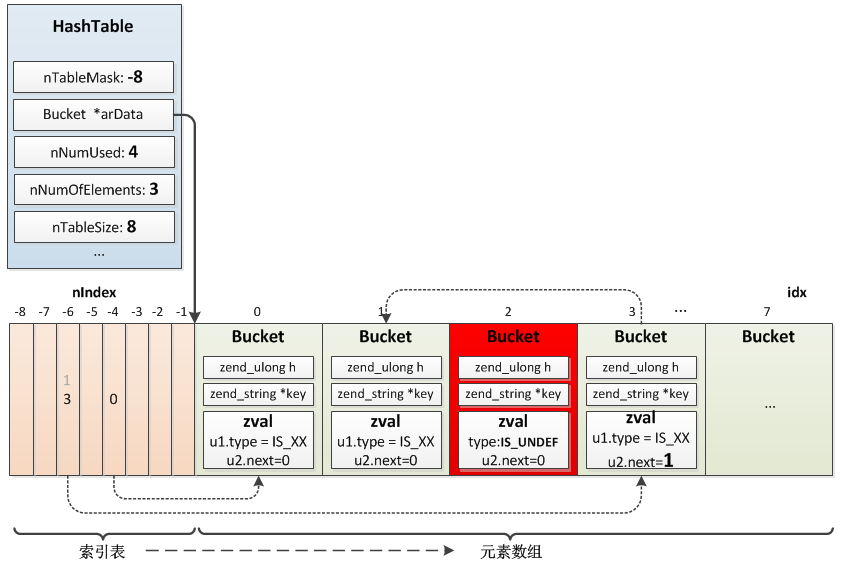
hash表实现(zend_hash.c)
这里首要分析了 数组的插入操作,插入的时候,是如何创建使用hash表的索引及选择bucket的位置的,插入操作主要通过 _zend_hash_add_or_update_i 实现的,如下:
首先先将一些可能会用用到的常量和函数先在这里声明一下,后面查看源码的时候会用到
1 | #define Z_NEXT(zval) (zval).u2.next |
源码如下:
1 | static zend_always_inline zval *_zend_hash_add_or_update_i(HashTable *ht, zend_string *key, zval *pData, uint32_t flag) |
从上面的api _zend_hash_add_or_update_i可以看出,其实更新操作很简单的,验证key是否存在,key存在的情况下如果值相等的话不做任何的操作,值不相同做更新操作。
这里比较重要的是hash表的新增,这里会涉及hash索引以及hash冲突链表。
nIndex = h | ht->nTableMask;
这里由于 nTableMask 是 -TableSize, 所以 nIndex 的计算结果范围,也就落到了-2^0 - -2^(tableSize-1)范围里从而将整个 arData 分成上图所示的左右两部分,左边是索引表,右边是元素数组,每次新增数据(非更新)的时候,首先把这个数据,顺序的插入到arData 右侧的元素数组里面,这样做的目的是为了保证数组的顺序性,在foreach的时候,只需要顺序遍历 arData 右侧的数组即可,但是这里有一个问题就是 查找怎么办, 所以就引入了arData 左侧的索引表,计算出key的hash索引,然后再指向 刚刚插入的arData右侧元素数组的地址
既然使用了hash表,就避免不了hash冲突的问题
1 | Z_NEXT(p->val) = HT_HASH_EX(arData, nIndex); |
结合上面可能用到的一些定义,这行就可以翻译成
1 | p->val.u2.next = *arData[nIndex] |
索引bucket指向新插入的元素,新插入的元素里阿米你的zval结构体里面的next指针再指向原先 索引bucket指向的位置,这样就把新插入的元素放在了冲突链表的头位置了
扩展-遍历
根据上面的插入思路,可以很清晰的看到,数组在内存中是个有序的数组,hash表实现了位置的索引,zval的u2结构体帮助实现了 hash冲突的链表解决方案
如果此时去遍历数组,就只需要顺序遍历arData的右侧元素数据即可,还是有序的