Go语言内置运行时(就是runtime),抛弃了传统的内存分配方式,改为自主管理,最开始是基于tcmalloc,虽然后面改动相对已经很大了。使用自主管理可以实现更好的内存使用模式,比如内存池、预分配等等,从而避免了系统调用所带来的性能问题。
在了解Go的内存分配之前,我们可以看一下内存分配的基本策略,来帮助我们理解Go的内存分配
基本策略:
- 每次从操作系统申请一大块内存,以减少系统调用
- 将申请的大块内存按照特定大小预先切成小块,构成链表
- 为对象分配内存时,从大小合适的链表中提取一块即可
- 如果对象销毁,则将对象占用的内存,归还到原链表,以便复用
- 如果限制内存过多,则尝试归还部分给操作系统,降低整体开销
下面我们从源码角度来分析Go的内存分配策略有何异同
准备
在追踪源码之前,我们需要首先了解一些概念和结构体
- span: 又多个地址连续的页(page)组成的大块内存
- object: 将span按特定大小切分成多个小块,每个小块可存储一个对象
对象分类
- 小对象(tiny): size < 16byte
- 普通对象: 16byte ~ 32K
- 大对象(large): size > 32K
大小转换

结构体
mHeap
代表Go程序持有的所有堆空间,Go程序使用一个mheap的全局对象_mheap来管理堆内存。
1 | type mheap struct { |
mSpanList
mSpan的链表,free busy busyLarge 上的mSpan都是通过链表串联起来的
1 | type mSpanList struct { |
mSpan
Go中内存管理的基本单元,是由一片连续的8KB的页组成的大块内存。注意,这里的页和操作系统本身的页并不是一回事,它一般是操作系统页大小的几倍。一句话概括:mspan是一个包含起始地址、mspan规格、页的数量等内容的双端链表。
1 | type mspan struct { |
spanClass
class表中的class ID,和Size Classs相关
1 | type spanClass uint8 |
mTreap
这个结构是包含mspan的树状结构,主要是给 freeLarge使用,在查找对应classsize的大对象的时候,使用树状结构查找要比链表更快
1 | type mTreap struct { |
mtreapNode
mTreap结构的节点,节点信息包含mspan和左右子节点等信息
1 | type treapNode struct { |
heapArena
heapArena存储的是arena的元数据, arenas是一组heapArena构成,所有的分配的内存都在 arenas 里面,大致 arenas[L1][L2] = heapArena, 而对于 分配出去的内存的 address,通过 arenaIndex 可以计算出 L1 L2, 从而找到该内存所对应的 arenas[L1][L2],即 heapArena
1 | type heapArena struct { |
arenaHint
这个是记录arena可以增长的地址
1 | type arenaHint struct { |
mcentral
mcentral则是全局资源,为多个线程服务,当某个线程内存不足时会向mcentral申请,当某个线程释放内存时又会回收进mcentral
1 | type mcentral struct { |
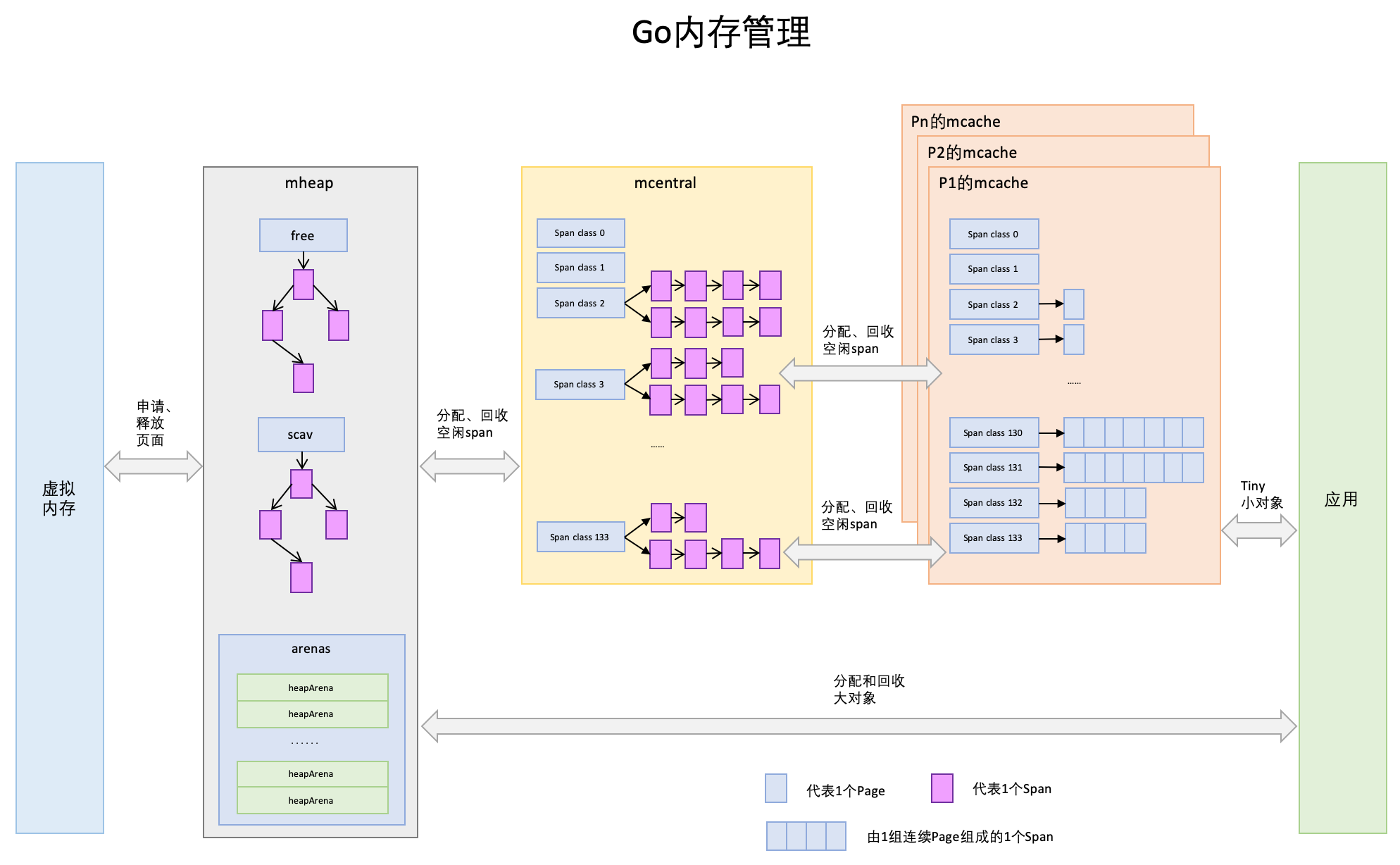
结构图
接下来,我们结合一下宏观的图示来理解一下上面的结构体之间的关联,同时对于后面的内存分配有一个简单的了解,等到后面全部讲完后,在回过头来看看这幅图,可能会对Go的内存分配有更清晰的认知
初始化
1 | func mallocinit() { |
mheap.init
1 | func (h *mheap) init() { |
mcentral.init
初始化某个规格的mcentral
1 | // Initialize a single central free list. |
allocmcache
mcache的初始化
1 | func allocmcache() *mcache { |
fixalloc.alloc
fixalloc是一个固定大小的分配器。主要用来分配一些对内存的包装的结构,比如:mspan,mcache..等等,虽然启动分配的实际使用内存是由其他内存分配器分配的。 主要分配思路为: 开始的时候一次性分配一大块内存,每次请求分配一小块,释放时放在list链表中,由于size是不变的,所以不会出现内存碎片。
1 | func (f *fixalloc) alloc() unsafe.Pointer { |
初始化的工作很简单:
- 初始化heap,初始化free large对应规格的链表,初始化busyLarge链表
- 初始化每个规格对应的mcentral
- 初始化mcache,对mcache里面每个对应的规格进行初始化
- 初始化 arenaHints,填充一组地址,后面根据真正的arena边界来进行扩增
分配
newObject
1 | func newobject(typ *_type) unsafe.Pointer { |
mallocgc
1 | func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer { |
整理一下 这段代码的基本思路:
首先判定 对象是 大对象 还是 普通对象还是 小对象
如果是 小对象
- 从 mcache 的alloc 找到对应 classsize 的 mspan
如果当前mspan有足够的空间,分配并修改mspan的相关属性(nextFreeFast函数中实现)
如果当前mspan没有足够的空间,从 mcentral重新获取一块 对应 classsize的 mspan,替换原先的mspan,然后 分配并修改mspan的相关属性
如果是普通对象,逻辑大致同小对象的 内存分配
首先查表,以确定 需要分配内存的对象的 sizeclass,并找到 对应 classsize的 mspan
如果当前mspan有足够的空间,分配并修改mspan的相关属性(nextFreeFast函数中实现)
如果当前mspan没有足够的空间,从 mcentral重新获取一块 对应 classsize的 mspan,替换原先的mspan,然后 分配并修改mspan的相关属性
如果是大对象,直接从mheap进行分配,这里的实现依靠
largeAlloc函数实现,我们先跟一下这个函数
largeAlloc
1 | func largeAlloc(size uintptr, needzero bool, noscan bool) *mspan { |
mheap.alloc
1 | func (h *mheap) alloc(npage uintptr, spanclass spanClass, large bool, needzero bool) *mspan { |
mheap.alloc_m
根据页数从 heap 上面分配一个新的span,并且在 HeapMap 和 HeapMapCache 上记录对象的sizeclass
1 | func (h *mheap) alloc_m(npage uintptr, spanclass spanClass, large bool) *mspan { |
mheap.allocSpanLocked
分配一个给定大小的span,并将分配的span从freelist中移除
1 | func (h *mheap) allocSpanLocked(npage uintptr, stat *uint64) *mspan { |
mheap.allocLarge
从 mheap 的 freeLarge 树上面找到一个指定page数量的span,并将该span从树上移除,找不到则返回nil
1 | func (h *mheap) allocLarge(npage uintptr) *mspan { |
注: 在看 《Go语言学习笔记》的时候,这里的查找算法还是 对链表的 遍历查找
mheap.grow
在 mheap.allocSpanLocked 这个函数中,如果 freelarge上找不到合适的span节点,就只有从 系统 重新分配了,那我们接下来就继续分析一下这个函数的实现
1 | func (h *mheap) grow(npage uintptr) bool { |
mheao.sysAlloc
1 | func (h *mheap) sysAlloc(n uintptr) (v unsafe.Pointer, size uintptr) { |
至此,大对象的分配流程至此结束,我们继续看一下,小对象和普通话对象的分配流程
小对象和普通对象分配
下面一段是 小对象和普通对象的内存查找和分配的主要函数,在上面的时候已经分析过了,下面我们就着重分析这两个函数
1 | span := c.alloc[spc] |
nextFreeFast
这个函数返回 span 上可用的地址,如果找不到 则返回0
1 | func nextFreeFast(s *mspan) gclinkptr { |
mcache.nextFree
如果 nextFreeFast 找不到 合适的内存,就会进入这个函数
nextFree 如果在cached span 里面找到未使用的object,则返回,否则,调用refill 函数,从 central 中获取对应classsize的span,然后 从新的span里面找到未使用的object返回
1 | func (c *mcache) nextFree(spc spanClass) (v gclinkptr, s *mspan, shouldhelpgc bool) { |
mcache.refill
Refill 根据指定的sizeclass获取对应的span,并作为 mcache的新的sizeclass对应的span
1 | func (c *mcache) refill(spc spanClass) { |
mcentral.cacheSpan
1 | func (c *mcentral) cacheSpan() *mspan { |
到这里,如果 从 mcentral 找不到对应的span,就开始了内存扩张之旅了,也就是我们上面分析的 mheap.alloc,后面的分析就同上了
分配小结
综上,可以看出Go的内存分配的大致流程如下
- 首先判定 对象是 大对象 还是 普通对象还是 小对象
- 如果是 小对象
- 从 mcache 的alloc 找到对应 classsize 的 mspan
- 如果当前mspan有足够的空间,分配并修改mspan的相关属性(nextFreeFast函数中实现)
- 如果当前mspan没有足够的空间,从 mcentral重新获取一块 对应 classsize的 mspan,替换原先的mspan,然后 分配并修改mspan的相关属性
- 如果mcentral没有足够的对应的classsize的span,则去向mheap申请
- 如果 对应classsize的span没有了,则找一个相近的classsize的span,切割并分配
- 如果 找不到相近的classsize的span,则去向系统申请,并补充到mheap中
- 如果是普通对象,逻辑大致同小对象的 内存分配
- 首先查表,以确定 需要分配内存的对象的 sizeclass,并找到 对应 classsize的 mspan
- 如果当前mspan有足够的空间,分配并修改mspan的相关属性(nextFreeFast函数中实现)
- 如果当前mspan没有足够的空间,从 mcentral重新获取一块 对应 classsize的 mspan,替换原先的mspan,然后 分配并修改mspan的相关属性
- 如果mcentral没有足够的对应的classsize的span,则去向mheap申请
- 如果 对应classsize的span没有了,则找一个相近的classsize的span,切割并分配
- 如果 找不到相近的classsize的span,则去向系统申请,并补充到mheap中
- 如果是大对象,直接从mheap进行分配
- 如果 对应classsize的span没有了,则找一个相近的classsize的span,切割并分配
- 如果 找不到相近的classsize的span,则去向系统申请,并补充到mheap中
参考资料
《Go语言学习笔记》